0x01 架构设计
本项目采用 c++ 语言开发,遵循 c++17 标准,实现了 RISC-V 结构和性能模拟器
流水线采用静态分支预测,同时对数据冒险做了处理使得无停顿(除了 load-use)
运行检查方法在第二部分
ELF 解析
使用开源项目 ELFIO 提供 elf 文件解析
一般只需要代码段.text和数据段.data和.sdata
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
ELFIO::elfio reader;
if (!reader.load(filename)) {
cerr << "Failed to open ELF file." << endl;
return 1;
}
vector<ELFIO::section*> useful_sections;
ELFIO::section* symtab_section = nullptr;
for (const auto& section : reader.sections) {
if (section->get_name() == ".text" ||
section->get_name() == ".data" ||
section->get_name() == ".rodata" ||
section->get_name() == ".sdata" {
// 注意 sbss, bss 段都是空
cout << section->get_name() << endl;
useful_sections.push_back(section.get());
}
if (section->get_name() == ".symtab") {
symtab_section = section.get();
}
}
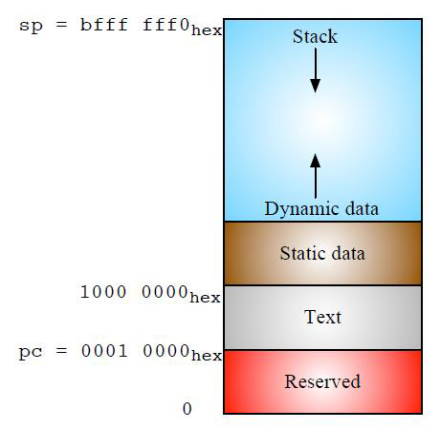
布局参考:
1
2
const size_t MEMORY_SIZE = 0x100000000;
vector<uint8_t> memory(MEMORY_SIZE, 0); // 内存
可以直接使用get_address()方法获取地址并直接映射到memory上,这个地址一般是 0x10000+,RISC-V 架构可执行文件的加载地址通常是 0x10000,就像 x86 架构可执行文件的加载地址是 0x8048000 和 0x400000 一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
vector<std::vector<uint8_t>> useful_section_data;
char* section_content;
for (const auto& section : useful_sections) {
section_content = (char*)section->get_data();
size_t section_length = section->get_size();
ELFIO::Elf64_Addr section_address = section->get_address();
if (section->get_data())
simulator.load(section_content, section_length, section_address);
}
void Simulator::load(const char* origin, uint64_t length, uint64_t address) {
vector<uint8_t> content(reinterpret_cast<const uint8_t*>(origin), reinterpret_cast<const uint8_t*>(origin + length));
memcpy(&memory[address], content.data(), content.size() * sizeof(uint8_t));
}
除了 x0 是恒为 0 的寄存器外,值得注意的是栈指针寄存器 x2 和全局指针寄存器(x3/gp),后者的位置通常是.sdata加上0x800的偏移,十进制是2048。如果没有正确设置 gp,会导致无法加载全局变量,参考:
数据通路
多周期处理器和流水线处理器均划分为 5 个阶段。
流水线处理器使用了四个中间寄存器:IF_ID, ID_EX, EX_MEM, MEM_WB,存储每个阶段结果和控制信号。由于工作量问题,并没有在所有阶段都使用信号控制,比如访存阶段依然是 switch 判断 opcode
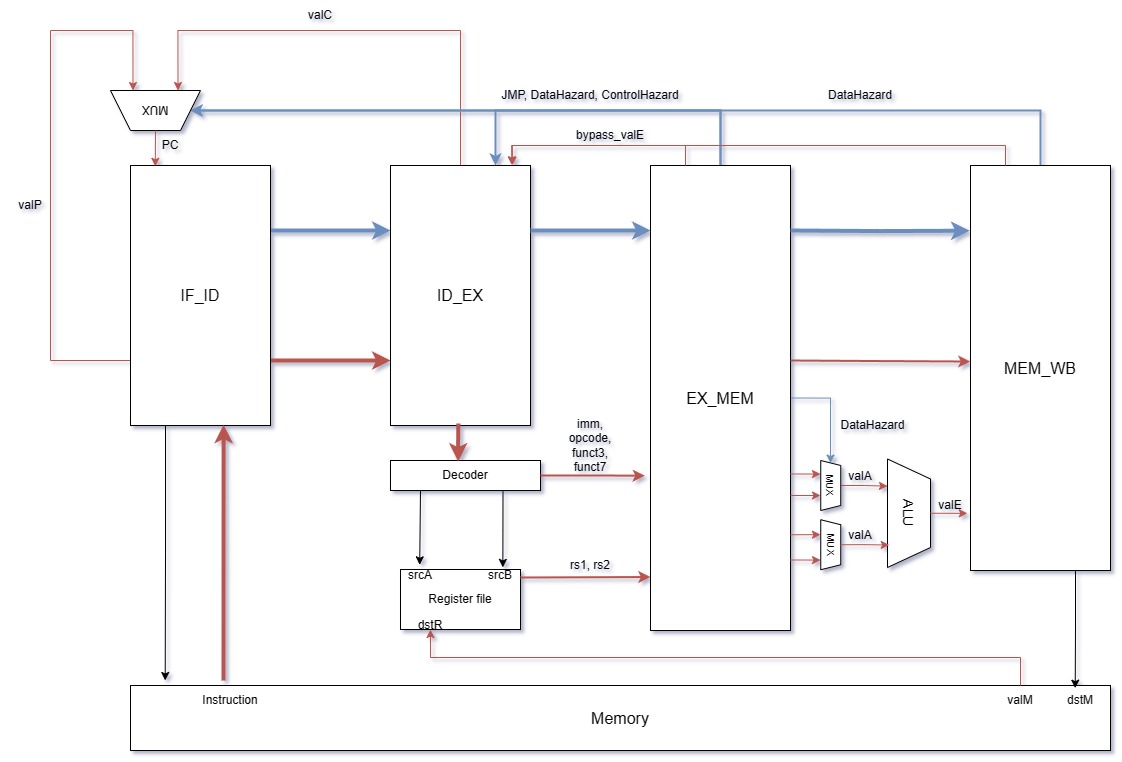
Hazard
| 类别 | 处理方法 |
|---|---|
| Data Hazard:Load-use | 在 decode 阶段检测,如果前一条指令是 load 且目的寄存器为本条指令的源寄存器,则阻塞两条指令(清空 ID_EX 寄存器,然后 fetch 阶段不取指令),如果前面第二条指令存在 load-use,则阻塞一条指令(清空 ID_EX 寄存器) |
| Data Hazard:RAW | 在 decode 阶段检测,srcA 和 srcB 存在数据冒险,则分别进行转发,流水线不停顿。 |
| Control Hazard | 将分支指令的跳转地址提前到 decode 阶段计算,在下一条指令的 decode 阶段检测,如果发现存在,则弹出一条指令(清空 ID_EX 寄存器),fetch 阶段使用跳转地址。无条件跳转指令采用同样处理方式,但不计入 Control Hazard。默认静态分支预测。 |
0x02 测试结果
打包文件中提供源代码、二进制文件和测试脚本:run.bat和run_no_pipeline.bat,可直接运行脚本查看所有程序运行的统计信息
编译命令(非必要):
g++ -std=c++17 -static -o Simulator.exe Simulator.cpp
g++ -std=c++17 -static -o Simulator_pipeline.exe Simulator_pipeline.cpp
示例
单步执行:
-
多周期:
.\Simulator.exe -s test1 -
流水线:
.\Simulator_pipeline.exe -s test1
-s 表示单步执行,这里没有存储和打印 WB 阶段结束后的信息
多周期处理器在 decode 后等待,而流水线处理器在每轮 fetch 结束后等待用户输入。
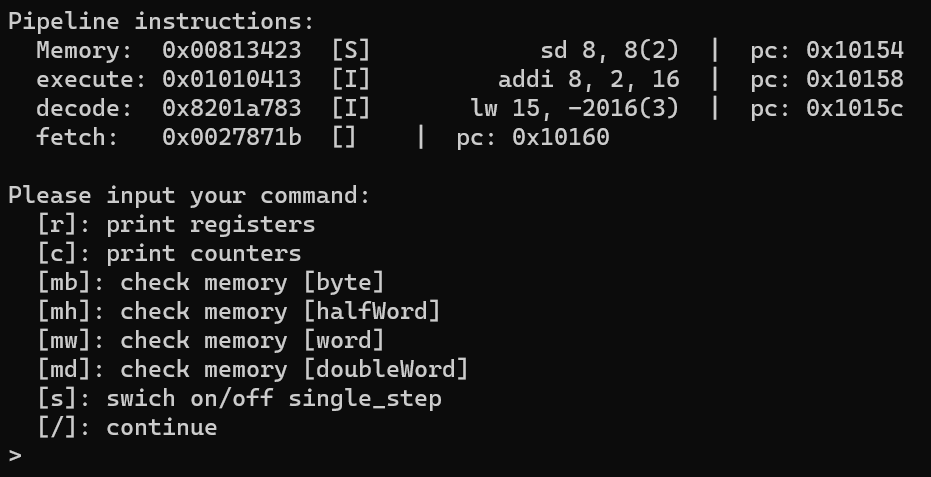
对阿克曼函数的测试结果:
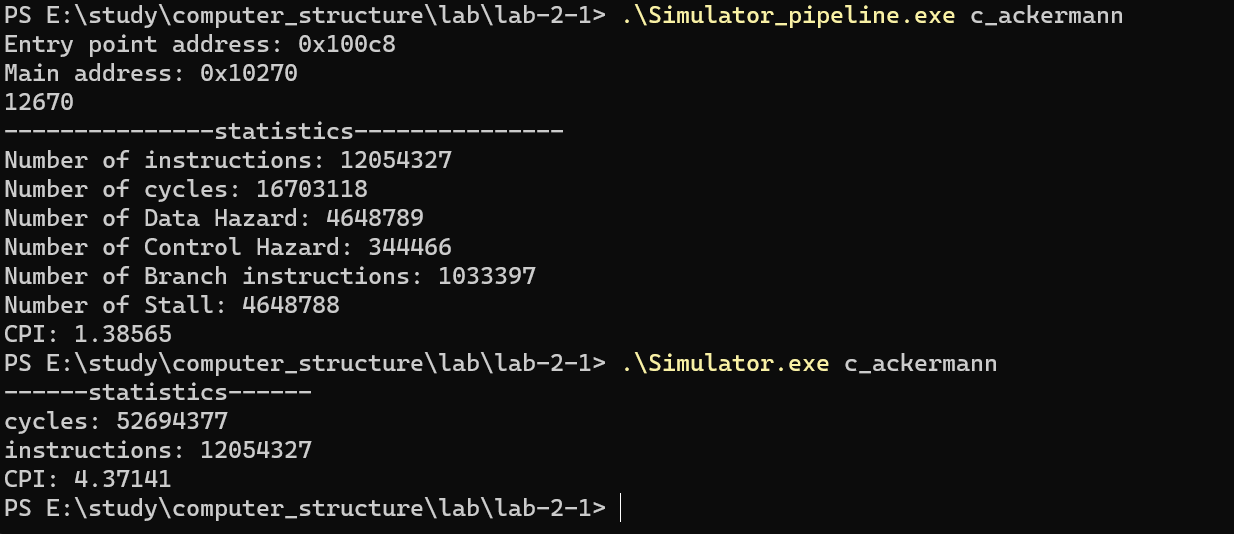
测试程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <stdio.h>
#define NUM_ITERATIONS 2
int ackermann(int m, int n) {
if (m == 0) {
return n + 1;
} else if (m > 0 && n == 0) {
return ackermann(m - 1, 1);
} else if (m > 0 && n > 0) {
return ackermann(m - 1, ackermann(m, n - 1));
}
return 0;
}
int main() {
int iter, result = 0;
int m = 3;
int n = 6;
for (iter = 0; iter < NUM_ITERATIONS; iter++) {
result = ackermann(m, n);
}
return 0;
}
多周期处理器
并非所有指令都划分成 5 个阶段,比如 R-Type 指令没有访存阶段,因此 CPI 可能小于 5
| 测试 | Instructions | Cycles | CPI |
|---|---|---|---|
| test1 | 29 | 133 | 4.58621 |
| test2 | 29 | 133 | 4.58621 |
| test3 | 118 | 517 | 4.38136 |
| test4 | 163 | 717 | 4.39877 |
| test5 | 119 | 716 | 6.01681 |
| test6 | 69 | 506 | 7.33333 |
| test7 | 133 | 586 | 4.40601 |
| test8 | 61 | 262 | 4.29508 |
| test9 | 34 | 193 | 5.67647 |
| test10 | 24 | 149 | 6.20833 |
流水线处理器
一般情况下,指令数越多,CPI 越趋向于 1,控制冒险和部分数据冒险会导致流水线停顿从而增大 CPI
| 测试 | Instructions | Cycles | CPI | Data Hazard | Control Hazard |
|---|---|---|---|---|---|
| test1 | 29 | 45 | 1.55172 | 9 | 0 |
| test2 | 29 | 45 | 1.55172 | 9 | 0 |
| test3 | 118 | 174 | 1.47458 | 67 | 1 |
| test4 | 163 | 239 | 1.46626 | 92 | 1 |
| test5 | 119 | 370 | 3.10924 | 66 | 1 |
| test6 | 69 | 300 | 4.34783 | 33 | 1 |
| test7 | 133 | 199 | 1.49624 | 71 | 1 |
| test8 | 61 | 85 | 1.39344 | 37 | 0 |
| test9 | 34 | 87 | 2.55882 | 9 | 0 |
| test10 | 24 | 75 | 3.125 | 7 | 0 |
0x03 具体实现
多周期执行顺序:fetch->decode->execute->accessMemory->writeBack
流水线执行顺序:writeBack->accessMemory->execute->decode->fetch
调试工具
riscv-software-src/riscv-isa-sim: Spike, a RISC-V ISA Simulator (github.com)
spike -d pk elf_rile:进入调试模式,回车能单步执行指令
util pc 0 0x10000:跳转 pc
reg 0:打印寄存器
mem 0 0xffffffff:打印内存地址
我们可以对比自己的模拟器和 spike 单步执行指令的结果来 debug
比较常见的错误:
-
decoder 逻辑错误
-
随机数未先扩展再使用
-
未能正确处理数据冒险和控制冒险
-
未能正确 load 和 save 数据
取指阶段
采用静态预测,默认从 ID_EX 寄存器中取出 valP 作为 PC,对于 Load-use 冒险会停顿,分支预测失败则从 EX_MEM 取出 valC 作为 PC。根据内存索引强制转换取出 32 位的 instruction,然后加法器计算出 valP 存储到 IF_ID 寄存器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
void fetch() {
// 初始清空寄存器
memset(&IF_ID, 0, sizeof(IF_ID));
if (EX_MEM.ControlHazard) {
// 分支预测失败, 优先度最高
IF_ID.pc = EX_MEM.valC;
} else if (ID_EX.JMP) {
// 无条件跳转需要停顿
// cout << "JMP Stall!" << endl;
stall_cnt++;
return;
} else if (EX_MEM.JMP) {
// cout << "JMP Success!" << endl;
if (EX_MEM.pc == EX_MEM.valC) {
// jal 0, 0
return;
}
IF_ID.pc = EX_MEM.valC;
} else if (EX_MEM.DataHazard3) {
// C3 停顿 2 条指令
stall_cnt++;
// cout << "load use!" << endl;
return;
} else if (MEM_WB.DataHazard3) {
IF_ID.pc = MEM_WB.valP;
} else if (MEM_WB.DataHazard4) {
// C4 停顿 1 条指令
IF_ID.pc = EX_MEM.valP;
} else {
// 默认下一条,这里相当于静态预测
IF_ID.pc = ID_EX.valP;
}
if (IF_ID.pc <= 0 || IF_ID.pc > 0x10000000) {
// cout << "Main end." << endl;
IF_ID.pc = 0;
return;
}
IF_ID.inst = *(reinterpret_cast<uint32_t*>(&memory[IF_ID.pc]));
IF_ID.valP = IF_ID.pc + 4;
// cout << hex << IF_ID.inst << endl;
inst_cnt++;
}
译码阶段
根据 switch 和移位进行译码,这里会访问通用寄存器取值
另外,所有的立即数使用前都先扩展到 64 位置:
1
2
3
4
5
6
7
8
int64_t signExt(uint64_t imm, uint8_t length) {
int64_t signBit = (imm >> (length - 1)) & 1;
if (signBit) {
int64_t mask = static_cast<int64_t>(-1) << length;
return imm | mask;
}
return static_cast<int64_t>(imm);
}
执行阶段
使用 lambda 表达式与 unordered_map 多级映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using ExecuteFunc = function<void(uint64_t operand1, uint64_t operand2)>;
using StringFunc = function<string(uint8_t rd, uint8_t rs1, int64_t rs2_or_imm)>;
// R-type
functionMap[0x33][0x0][0x00] = [this](uint64_t rs1, uint64_t rs2) {
EX_MEM.valE = ADD_FUNC(uint64_t, rs1, rs2);
};
instructionMap[0x33][0x0][0x00] = [this](uint8_t rd, uint8_t rs1, int64_t rs2) {
string result = "add " + to_string(rd) + ", " + to_string(rs1) + ", " + to_string(rs2);
return result;
};
//...
unordered_map<uint8_t, unordered_map<uint8_t, unordered_map<uint8_t, ExecuteFunc>>> functionMap;
unordered_map<uint8_t, unordered_map<uint8_t, unordered_map<uint8_t, StringFunc>>> instructionMap;
执行前会检查数据冒险,据此传入 bypass_valA/valA 以及 bypass_valB/valB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
void execute() {
EX_MEM = ID_EX;
uint8_t opcode = EX_MEM.opcode;
uint8_t funct3 = EX_MEM.funct3;
uint8_t funct7 = EX_MEM.funct7;
if (opcode == 0x37) {
EX_MEM.valE = EX_MEM.valB;
return;
}
if (opcode == 0x73) {
return;
}
uint64_t valA = EX_MEM.valA;
uint64_t valB = EX_MEM.valB;
if (EX_MEM.DataHazard1) {
valA = EX_MEM.bypass_valA;
}
if (EX_MEM.DataHazard2) {
valB = EX_MEM.bypass_valB;
}
functionMap[opcode][funct3][funct7](valA, valB);
}
访存阶段
访问 memory[dstM] 写入或者取出值到 valM 即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
void accessMemory() {
uint8_t byteData;
uint16_t halfData;
uint32_t wordData;
uint64_t dwordData;
int64_t signExtendedData;
MEM_WB = EX_MEM;
if (EX_MEM.opcode == 0x03) {
switch (EX_MEM.funct3) {
case 0x0:
byteData = memory[EX_MEM.dstM];
signExtendedData = static_cast<int8_t>(byteData);
break;
case 0x1:
halfData = *reinterpret_cast<uint16_t*>(&memory[EX_MEM.dstM]);
signExtendedData = static_cast<int16_t>(halfData);
break;
case 0x2:
wordData = *reinterpret_cast<uint32_t*>(&memory[EX_MEM.dstM]);
signExtendedData = static_cast<int32_t>(wordData);
break;
case 0x3:
dwordData = *reinterpret_cast<uint64_t*>(&memory[EX_MEM.dstM]);
signExtendedData = static_cast<int64_t>(dwordData);
break;
default:
throw("Invaild Instruction at %x, The Func Field %x is invaild\n", MEM_WB.pc, MEM_WB.inst);
break;
}
MEM_WB.valM = signExtendedData;
if (single_step) {
cout << "Load data from memory[" << to_string(EX_MEM.dstM) << "]" << endl;
}
return;
} else if (EX_MEM.opcode == 0x23) {
switch (EX_MEM.funct3) {
case 0x0:
memory[EX_MEM.dstM] = static_cast<uint8_t>(registers[EX_MEM.srcR2]);
break;
case 0x1:
halfData = static_cast<uint16_t>(registers[EX_MEM.srcR2]);
memcpy(&memory[EX_MEM.dstM], &halfData, sizeof(uint16_t));
break;
case 0x2:
wordData = static_cast<uint32_t>(registers[EX_MEM.srcR2]);
memcpy(&memory[EX_MEM.dstM], &wordData, sizeof(uint32_t));
break;
case 0x3:
memcpy(&memory[EX_MEM.dstM], ®isters[EX_MEM.srcR2], sizeof(uint64_t));
break;
default:
throw("Invaild Instruction at %x, The Func Field %x is invaild\n", MEM_WB.pc, MEM_WB.inst);
break;
}
if (single_step) {
cout << "Save data at memory[" << to_string(EX_MEM.dstM) << "]" << endl;
}
return;
}
}
写回阶段
根据 RegWr 判断是否需要写回 dstM,Load 指令写回 valM,无条件跳转指令写回 valP,其他指令写回 valE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
void writeBack() {
if (!MEM_WB.RegWr) {
// Don't write registers
return;
}
if (MEM_WB.dstR == 0) {
return;
}
if (MEM_WB.MemtoReg) {
// Load
registers[MEM_WB.dstR] = MEM_WB.valM;
return;
}
if (MEM_WB.JMP || (MEM_WB.Branch && MEM_WB.Zero)) {
// JAL or JALR
registers[MEM_WB.dstR] = MEM_WB.valP;
return;
}
// ALU
registers[MEM_WB.dstR] = MEM_WB.valE;
}
0x04 参考
- ELFIO - ELF reader and producer implemented as a header only C++ library (github.com)
- 清华:RISC-V 指令概况 - 计算机组成原理(2021年) (tsinghua.edu.cn)
- 第 9 章 指令流水线 计算机体系结构基础 (foxsen.github.io)
- Reading-Notes/CSAPP/4.处理器体系结构.md at master · LunarNight/Reading-Notes (github.com)
- Pipelining_2_DSF.ppt (utexas.edu)
- Using C++ Emulator fails when calling printf syscall from a RISC-V baremetal program - Stack Overflow
- system calls - RISC-V ecall syscall calling convention on pk/Linux - Stack Overflow
- Berkeley:HTU2.indd (berkeley.edu)
- Icarusradio/cs61c-risc-v-emu at fa17 (github.com)
- riscv-spec.pdf
- HTU2.indd (berkeley.edu)
- (Mis)understanding RISC-V ecalls and syscalls Juraj’s Blog (jborza.com)
- syscall implementation (google.com)
- MIPS: Computer Architecture and Organization - Shuai Wang (nju.edu.cn)
- RV64I Instructions — riscv-isa-pages documentation (msyksphinz-self.github.io)