0x01 评测程序
针对系统评测的不同目标会采用不同的评测程序。在目前已有的评测程序中,为下列评测目标找到合适的评测程序(列出即可)。
| 目标 | 程序 | 目标 | 程序 |
|---|---|---|---|
| CPU整点性能 | SPEC CPU 2017 | CPU浮点性能 | SPEC CPU 2017 |
| 计算机事务处理能力 | TPC-C/TPC-E SPECjEnterprise 2010 |
嵌入式系统计算能力 | Embench, CoreMark, Dhrystone |
| 2D处理能力 | PerformanceTest (PassMark) | 3D处理能力 | SPECapcfor 3ds Max2020 |
| 并行计算性能 | SPEC ACCEL | 系统响应速度 | Loadrunner |
| 编译优化能力 | SPEC ACCEL | 操作系统性能 | Sysbench |
| 多媒体处理能力 | Media eXperience Analyzer | IO处理能力 | iozone/iometer |
| 浏览器性能 | Speedometer | 网络传输速率 | netperf |
| Java运行环境性能 | SPECjbb 2015 | 邮件服务性能 | Apache JMeter |
| 服务器功耗和性能 | SPECpower_ssj 2008 | Web服务器性能 | Apache JMeter |
SPEC CPU 2017 包含四个套件:
-
SPECspeed 2017 Interger
-
SPECspeed 2017 Floating Point
-
SPECrate 2017 Interger
-
SPECrate 2017 Floating Point
主要用于测试整数和浮点计算性能,speed单任务速率/rate多任务吞吐量
SPEC ACCEL专注于高度并行计算的性能,使用硬件加速的密集型应用程序
SPECapcfor 3ds Max2020 通过建模、交互式图形和视觉效果全面测量 CPU 和 GPU 性能
TPC-C实现了订单输入工作负载,具有更复杂的实时和批处理事务,并引入了具有响应时间约束的客户端/服务器模型的概念。 TPC-E 实现了股票交易工作负载,具有多阶段交易事务和大量只读事务,代表向混合环境的转变。
Dhrystone和Coremark已经成为过去三十年来微控制器基准测试套件的事实标准,但这些基准测试现在不再反映现代嵌入式系统的需求。Embench™是专门设计用来满足现代连接的嵌入式系统的要求的。这些基准测试是相关的、可移植的,并且实施得很好。
0x02 阅读文献
阅读文献(Reinhold P.Weicker, An Overview of Common Benchmarks, IEEE Computer, December 1990.)并回答下面的问题
1) 简述用于性能评测的MIPS指标之含义,以及它是如何被计算的。
-
MIPS 是一种常用的性能评测指标,字面意义即每秒执行的百万条指令数(Million Instructions Per Second),也称为 Native MIPS。对于不同指令集架构而言,Native MIPS 的比较毫无意义。因此MIPS常常被重新定义为 VAX MIPS,即比较其他机器和 VAX 11/780 执行程序的相对速度(X-MIPS 相对速度为 VAX 11/780 的 X 倍)。有时新微处理器的产品公告中会出现 Peak MIPS,对于大多数处理器来说,Peak MIPS 等同于时钟频率,因此对性能评测没有太大意义。
-
Dhrystone MIPS, EDN MIPS 指运行特定(测试)程序时得到的 Native MIPS 或 VAX MIPS
2) 使用linux下的剖视工具(例如gprof)对dhrystone和whetstone进行剖视,参考论文Table 1形式给出数据,你的结果和该论文是否一致?如有不同,请说明原因。
Dhrystone
dhrystone 2.1 下载地址:https://fossies.org/linux/privat/old/dhrystone-2.1.tar.gz
-
修改makefile:
-
在CFLAGS和GCCFLAGS后加入
-pg -static选项(static选项便于我们分析gcc的库函数) -
TIME_FUNC设置为
-DTIMES或者-DTIME,区别是使用的计时函数不同,前者使用ticks(时钟滴答),后者使用clock返回程序运行秒数,早期ticks是CPU时钟周期(1/frequency)的同义词,但现在在Linux中HZ一般被固定为 100,换句话说ticks精确到0.01s. 参考:unix - What is a CPU tick? - Super User
-
-
make前还需要修改 dhry_1.c:48 为
extern clock_t times(); -
运行
./gcc_dry2,输入$10^9$(一百亿)执行,产生一个gmon.out文件 -
gprof gcc_dry2 gmon.out > profile.txt得到报告
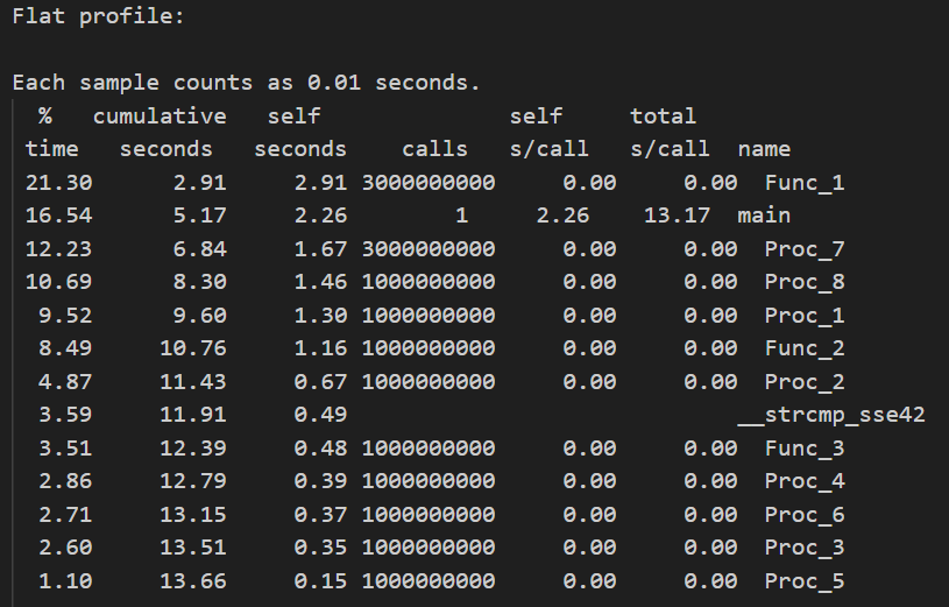

Main程序所占的时间相近,strcmp所占用的时间更短,问题是strcpy不见了。
测试程序中一共只在 main 中出现过 4 次 strcpy,前两回是初始化,只调用 1 次。
第三回strcpy (Str_2_Loc, “DHRYSTONE PROGRAM, 2‘ND STRING”); 会调用程序循环次数,而第四回strcpy (Str_2_Loc, “DHRYSTONE PROGRAM,
3‘RD STRING”);不会调用,因为判断条件为永假。这段不会执行的代码的存在意义实际是使得编译器不会将 Str_2_Loc 直接进行常量传播/-fmerge-constants),但是编译器在这里依然将 strcpy 变成了 a sequence of word moves(应该和GCC版本有关)
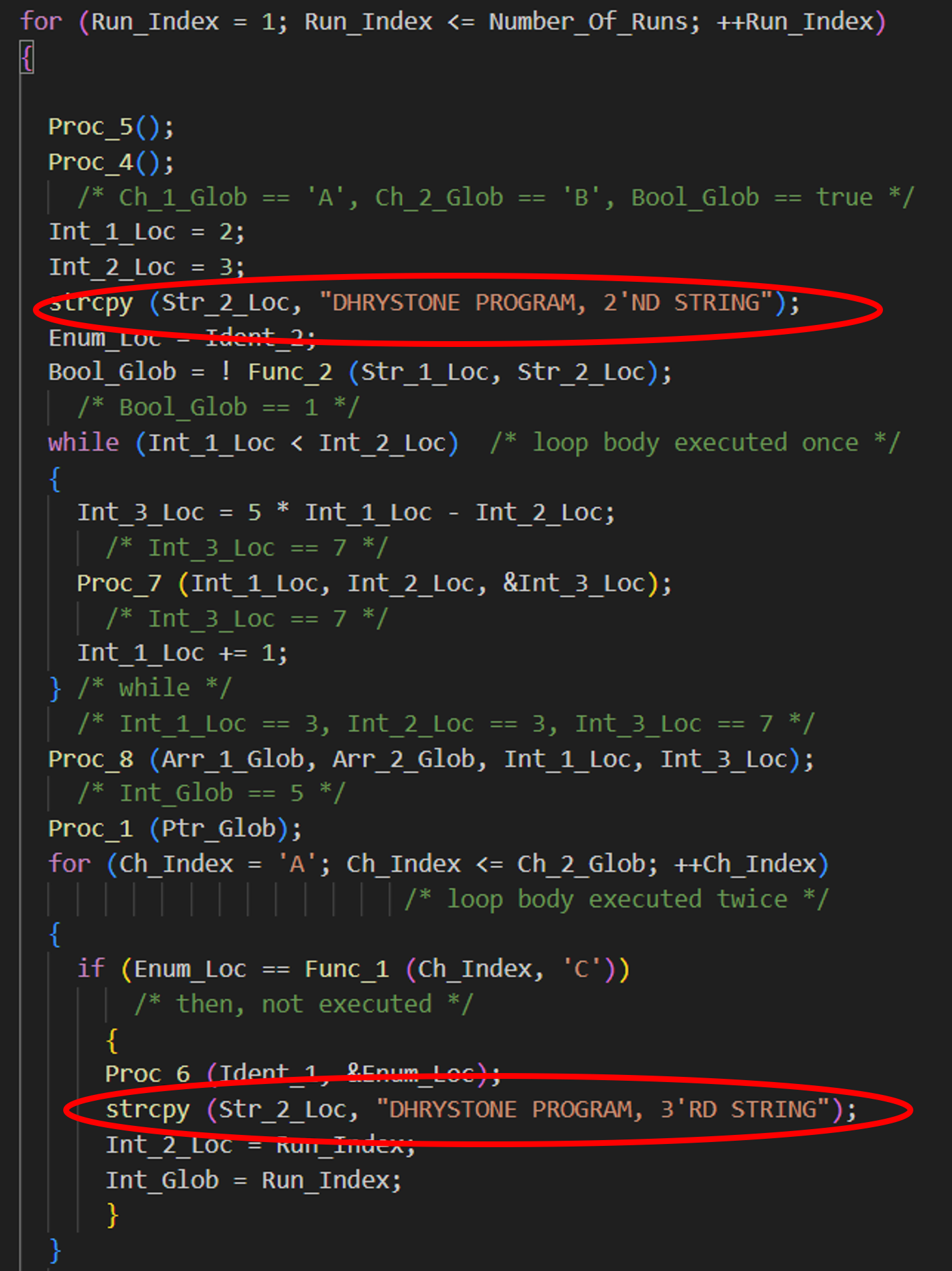
查看汇编代码,strcpy进行了3次8字节、1次4字节、1次2字节、1次1字节的move。而正常strcpy应该逐字节拷贝。
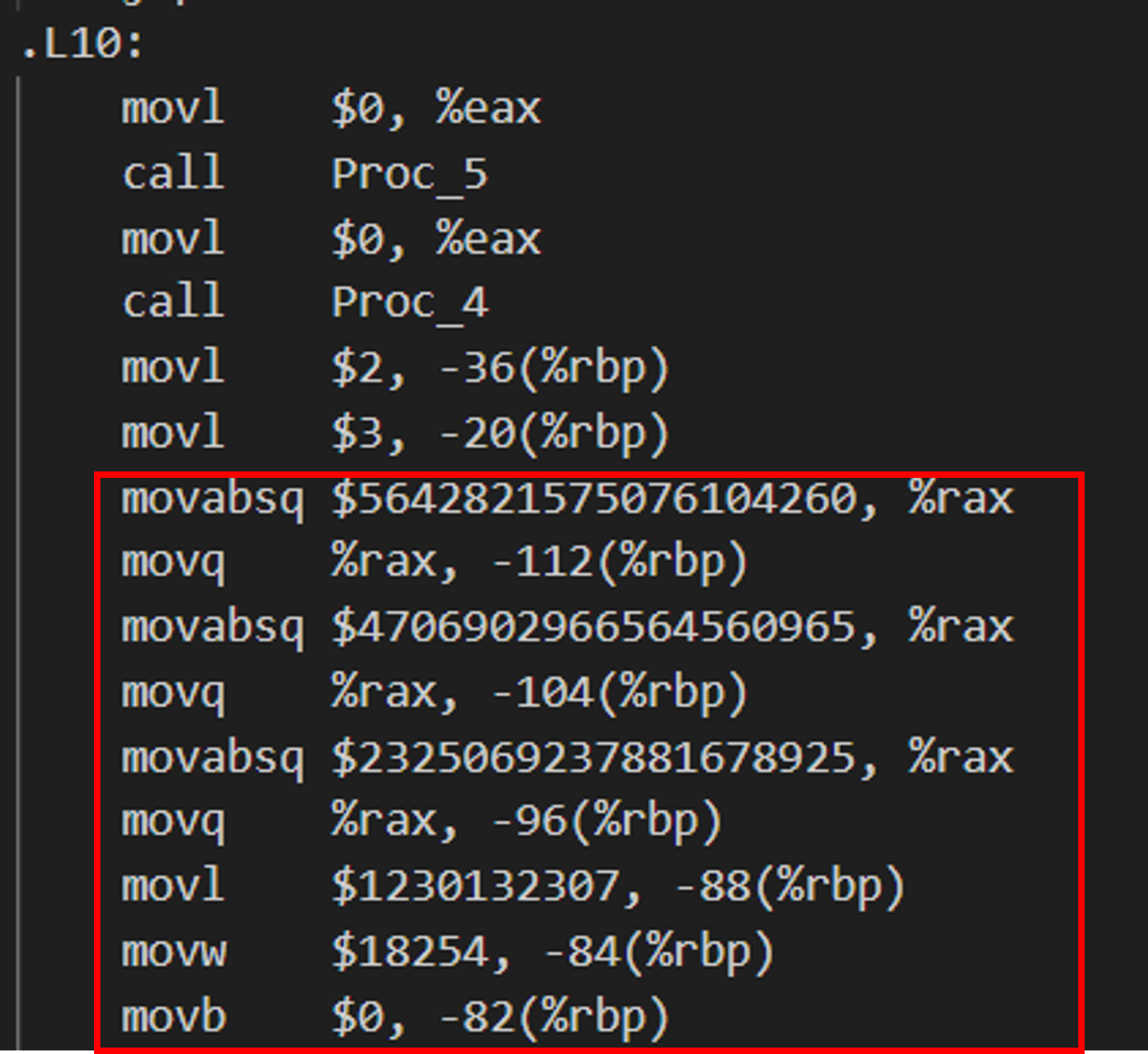
解决方法是使用字符数组代替常量字符串:
1
2
3
char dhry_str2[] = "DHRYSTONE PROGRAM, 2'ND STRING";
…
strcpy (Str_2_Loc, dhry_str2);
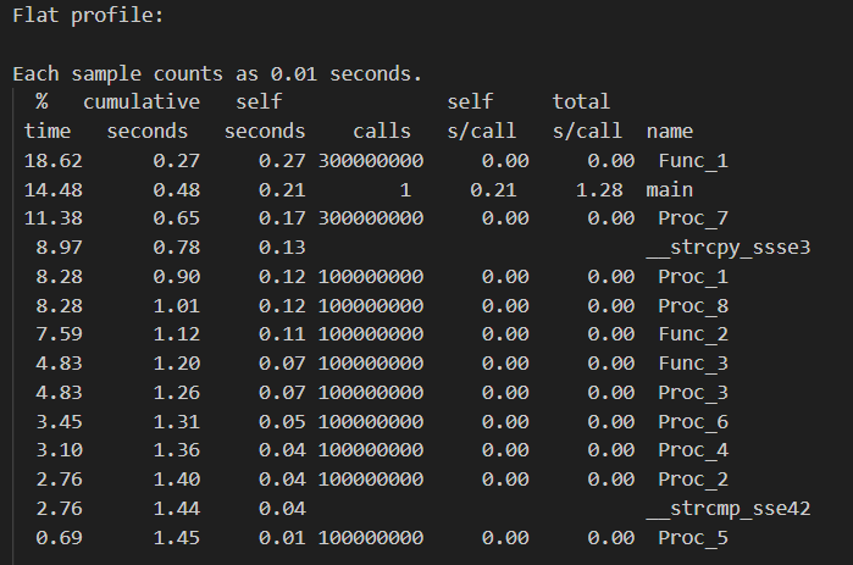
Strcpy 占比 8.97%,与论文数据接近
Whetstone
gcc whet.c –o whet –lm –static -pg
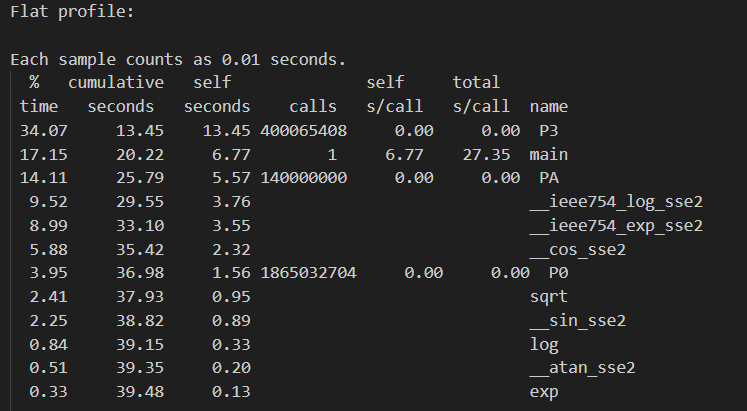
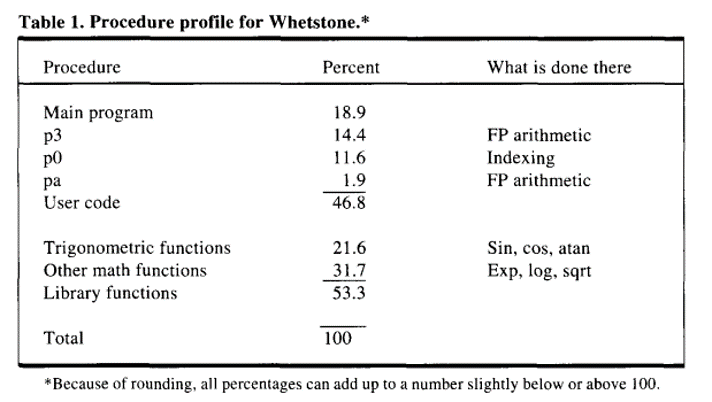
P0 的比例远远低于论文,而 P0 是简单的3个全局变量交换内容,涉及到访存,因此猜测和机器的缓存有关。
3) 论文中讨论了CPU之外可能对性能造成影响的几种因素。请阐述文中不同编程语言对程序性能影响的观点,并分别使用两种不同的语言(例如C和Java)使用相同算法实现快速排序、矩阵乘法、求Ackermann函数,验证以上观点。(请保留你的程序,我们在后面可能还会用到它)
影响性能的因素:
-
编程语言:论文中提到语言特性(调用顺序、指针语义和字符串语义)会影响执行时间
-
调用顺序:(串行|并行)Python由于存在全局解释所(GIL)无法在单一进程中利用多线程提高CPU密集型指令的执行效率,而在C++中则不然
-
指针语义:(值传递|引用传递)引用传递更加高效,减少了复制开销
-
字符串语义:(可变字符串|不可变字符串)部分语言如JavaScript中每次对字符串修改都会创建一个新的字符串对象,效率低下
-
其他:编译性语言(如:C)快于解释性语言(如:Python),因为前者会在编译时优化成机器代码,因此性能更好
-
-
编译器:不同的编译器实现了不同的编译优化和代码生成策略,文章中提到旧的Unix编译器速度要比VMS编译器慢多达30%,GCC本身也提供了O1到O3多种优化策略
- 注意到论文中提到了O4优化会进行过程内联,然而现版本的gcc并不存在O4,且在O2就进行了过程内联,stackoverflow上认为这可能是PGCC遗留
-
Runtime library system
-
运行时库区别于一般的静态库(Static)或者动态库(Dynamic Library),运行时库是编程语言或操作系统提供的一组低级例程(malloc, enum, struct, abs, min, assert…),我们可以在不引入任何标准库的情况下编译执行包含这些低级例程的文件
-
编译期间可用的头文件(论文中指的是 #include
和 #include ) What is the C runtime library? - Stack Overflow
c++ - What specifically is a runtime library? - Stack Overflow
-
例:glibc的默认数学库遵循IEEE浮点标准,但同时提供了一个更快的矢量数学库libmvec,使用
-ftree-loop-vectorize-ffast-math能开启这种优化python的math、cmath、numpy库的区别;
-
-
Cache size:如果缓存小于相关基准大小,对代码进行重新排序可能会在某些基准测试和缓存配置下节省执行时间。在MC 68020系统上对Whetstone进行源程序重新排序,在NS 32532上对Dhrystone进行链接顺序不同也会导致执行时间高达5%的不同。对于哪种情况更能代表系统的真实特性存在争议。
算法:
-
快速排序:使用srand生成$10^6$个随机整数存放在文件中,循环执行50次,
C所用总时间为5.07s,平均时间0.1014s,Python所用总时间为81.894947s,平均时间为1.637899s,C的速度是Python的16倍 -
矩阵乘法:使用朴素的$n^3$算法,计算两个 $1000\times1000$ 的整数矩阵乘积,循环执行50次,
C所用总时间为92.80s,平均时间1.856s,Python在不使用numpy的情况下实在是太慢了,我只能设置执行1次,所用时间为65.394213s,C的速度是Python的35倍 -
Ackermann函数:由于
A(4, 1)的递归深度远大于Python2的默认递归深度(1000),这里采取计算A(3,6),循环执行1000次,C所用总时间为0.35s,平均时间0.00035s,Python所用总时间为11.117494s,平均时间0.011117s,C的速度是Python的31倍-
被指出这里的递归深度实际上应该是堆栈大小,即实际递归深度达到不了设置的堆栈大小,当然
sys.setrecursionlimit()这个函数的称呼很具有迷惑性。参考:Python max recursion, question about sys.setrecursionlimit() - Stack Overflow -
另外,计算
A(4,1)时,python 2.7会在执行过程中无报错的情况下退出,使用 python 3.11 则不会。
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import time
import sys
sys.setrecursionlimit(100000)
# NUM_ITERATIONS = 1000
def ackermann(m, n):
if m == 0:
return n + 1
elif m > 0 and n == 0:
return ackermann(m - 1, 1)
elif m > 0 and n > 0:
return ackermann(m - 1, ackermann(m, n - 1))
return 0 # invalid
if __name__ == "__main__":
m = 4
n = 1
start_time = time.time()
result = ackermann(m, n)
end_time = time.time()
total_time = end_time - start_time
# average_time = total_time / NUM_ITERATIONS
print "Ackermann(%d, %d) = %d" %(m, n, result)
print "total time: %f" %(total_time)
# print "Average ackermann time over %d iterations: %f seconds" % (NUM_ITERATIONS, average_time)
0x03 性能评测
一、工作背景和评测目标
本实验是在 Lenovo R9000P 2023上对 Virtualbox 虚拟机中的 CentOS7 进行评测
物理机操作系统为 Microsoft Windows 11专业版,虚拟机实际分配CPU数量为 6,内存大小为 8GB,外存大小为 20GB
后来又在物理机切换操作系统成 Ubuntu 22.04 LTS 重新进行评测
二、评测环境
| 项目 | 详细指标和参数 | |
|---|---|---|
| 处理器型号及相关参数(频率、架构、缓存等) | AMD Ryzen 9 7945HX with Radeon Graphics Cpu cores: 16 Cpu MHz: 2495.272 Microarchitecture:Zen 4(IS: x86-64) Cache size: 1024 KB |
|
| 内存 | 32GB RAM (虚拟机:8GB) | 32GB RAM |
| 外存 | SKHynix_HFS001TEJ9X115N | Samsung SSD 990 PRO 1TB |
| 操作系统及其版本 | CentOS Linux release 7.9.2009 (Core) | Ubuntu 22.04.3 LTS |
| 编译器版本及编译参数 | gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) | gcc version 11.4.0 (Ubuntu 11.4.0-1ubuntu1~22.04) |
| 库函数及其版本 | libgcc-4.8.5-44.el7 这里应该是glibc(标准库)而不是libgcc(运行时库)才正确,但现在偷懒就不上虚拟机看了 |
libgcc-11.4.0 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
cat /proc/version
uname -a # 查看操作系统
cat /etc/redhat-release # 查看redhat发行版本
cat /etc/centos-release # 查看centos发行版本
lsb_release -a # 查看ubuntu发行版本
cat /etc/os-release # 通用
cat /etc/cpuinfo # 查看cpu信息
rpm -qa | grep gcc` # 查看gcc及库函数版本
rpm -q --queryformat "%{NAME}-%{VERSION}-%{RELEASE}\n" libgc`
dpkg-query -l | grep libgcc # ubuntu查看库函数版本
Windows DX诊断:win+r 输入 dxdiag
三、评测步骤及结果分析
1. Dhrystone
1.1 在linux下基于dhrystone-2.1所提供的Makefile编译dhrystone
1.2 分别采用$10^8、310^8、510^8、710^8、910^8$为输入次数,运行编译生成的两个程序,记录、处理相关数据并做出解释
Dhrystone 在 VAX 11/780 每秒执行Dhrystone的数量为1757,因此使用下面的公式作为评价标准:
\[DMIPS=\frac{Dhrystones per Second}{1757}\]| OS | CentOS | 虚拟机 | Ubuntu | 物理机 |
|---|---|---|---|---|
| loop | gcc_dry2 | gcc_dry2reg | gcc_dry2 | gcc_dry2reg |
| $10^8$ | 4541 | 5212 | 17786 | 21477 |
| $3*10^8$ | 4649 | 5230 | 17917 | 22705 |
| $5*10^8$ | 4764 | 5307 | 18137 | 23155 |
| $7*10^8$ | 4728 | 5279 | 17834 | 22871 |
| $9*10^8$ | 4751 | 5286 | 17929 | 23022 |
(数据保留整数)
-
物理机性能是虚拟机的 4 倍左右
-
可以观察到循环从 $10^8$ 到 $$5*10^8$ 后,
gcc_dry2性能略有所提升,猜测与缓存热身有关,之后继续增加循环,性能指标趋于稳定,受到系统资源竞争、外部干扰的影响降低 -
O0下不涉及寄存器优化,因此
gcc_dry2reg的性能高于gcc_dry2约10%
1.3 对dhrystone代码进行三行内的修改,使其运行结果不变但“性能”提升。
① 使用增量/减量操作符和复合赋值表达式进行优化
-
164行:
Int_1_Loc++; -
183行:
Int_2_loc *= Int_1_loc; -
341行:
Int_Loc--;
| loop | gcc_dry2(优化后) | gcc_dry2reg(优化后) |
|---|---|---|
| $10^8$ | 4780 | 5249 |
| $3*10^8$ | 4794 | 5342 |
| $5*10^8$ | 4802 | 5332 |
| $7*10^8$ | 4806 | 5335 |
| $9*10^8$ | 4811 | 5343 |
平均 DMIPS 由4966.4到5052.7提升了 86.3,1.74%
② 注释掉 189 行 strcpy (Str_2_Loc, "DHRYSTONE PROGRAM, 3'RD STRING");使得编译器进行常量传播
| loop | gcc_dry2(优化后) | gcc_dry2reg(优化后) |
|---|---|---|
| $10^8$ | 4881 | 5280 |
| $3*10^8$ | 4874 | 5345 |
| $5*10^8$ | 4890 | 5367 |
| $7*10^8$ | 4879 | 5369 |
| $9*10^8$ | 4882 | 5371 |
平均 DMIPS 由4966.4到5108.5提升了142.1,2.86%
③ dhry_2.c 的 Proc_8 中存在一个只进行两次的循环,可以展开提高效率
1.4 讨论采用dhrystone进行评测存在哪些可以改进的地方,对其做出修改、评测和说明。
根据网络上的Dhrystone测试结果集,编译器优化对性能测试的结果相当大,甚至能达到数倍。Dhrystone 中的 string 是已知的恒定长度,且开始时对齐,这是实际程序中通常没有的两个特征,因此,编译器可以将字符串拷贝替换为没有任何循环的 a sequence of word moves,这种优化夸大了系统性能,有时甚至超过 30%
按照先前提到的用字符数字代替字符串常量的方法修改:
| loop | gcc_dry2(字符数组) | gcc_dry2reg(字符数组) |
|---|---|---|
| $10^8$ | 4436 | 4953 |
| $3*10^8$ | 4465 | 4960 |
| $5*10^8$ | 4458 | 4982 |
| $7*10^8$ | 4464 | 4973 |
| $9*10^8$ | 4461 | 4979 |
平均 DMIPS 由4966.4到4706.1下降了5.24%
2. Whetstone
2.1 在linux下使用编译器分别采用-O0、-O2、-O3选项对whetstone程序进行编译并执行,记录评测结果。
1
2
3
4
5
6
7
wget -O whet.c http://www.netlib.org/benchmark/whetstone.c
gcc -O0 whet.c -o whet0 -lm
gcc -O2 whet.c -o whet2 -lm
gcc -O3 whet.c -o whet3 -lm
./whet0 -c 1000000
./whet2 -c 1000000
./whet3 -c 1000000
2.2 分别采用$10^6、10^7、10^8$为输入次数,运行编译生成的可执行程序,记录、处理相关数据并做出解释。
修改 loopstart 后运行:
1
(./whet0 & ./whet2 & ./whet3 &)
| loop | optimize | Duration | MIPS |
|---|---|---|---|
| $10^6$ | O0 | 14 | 7142.9 |
| $10^6$ | O2 | 5 | 20000 |
| $10^6$ | O3 | 5 | 20000 |
| $10^7$ | O0 | 138 | 7246.4 |
| $10^7$ | O2 | 50 | 20000 |
| $10^7$ | O3 | 48 | 20833.3 |
| $10^8$ | O0 | 1426 | 7012.6 |
| $10^8$ | O2 | 542 | 18450.2 |
| $10^8$ | O3 | 516 | 19379.8 |
可以观察到随着循环增多,数据更加稳定和精确,O0 到 O2 的优化明显,而 O2 到 O3 的优化并不明显。这可能是因为 O2 已经解决了程序的性能瓶颈,比如代码局部性和寄存器优化,而 O3 主要是复杂的循环优化和全局优化,对于 Whetstone没有显著提升。
-
被指出这里 O0 到 O2 的提升过于明显,和程序中的宏有关系(?),当然我是没太听懂
- 然后我把
#define DSIN sin等几个三角函数的宏定义去掉,直接调用sin发现确实是有一定的影响。即开启宏以后,在O2阶段就会把sin内建到程序中(汇编中不再出现call sin),而正常这应当是O3应当做的事情,所以可以在O2时加入fno-builtin,或者直接把宏全部去掉
- 然后我把
2.3 进一步改进whetstone程序性能(例如新的编译选项),用实验结果回答。
| loop | optimize | Duration | MIPS |
|---|---|---|---|
| $10^6$ | Ofast | 1 | 100000 |
| $10^7$ | Ofast | 12 | 83333.3 |
| $10^8$ | Ofast | 121 | 82644.6 |
3. iozone
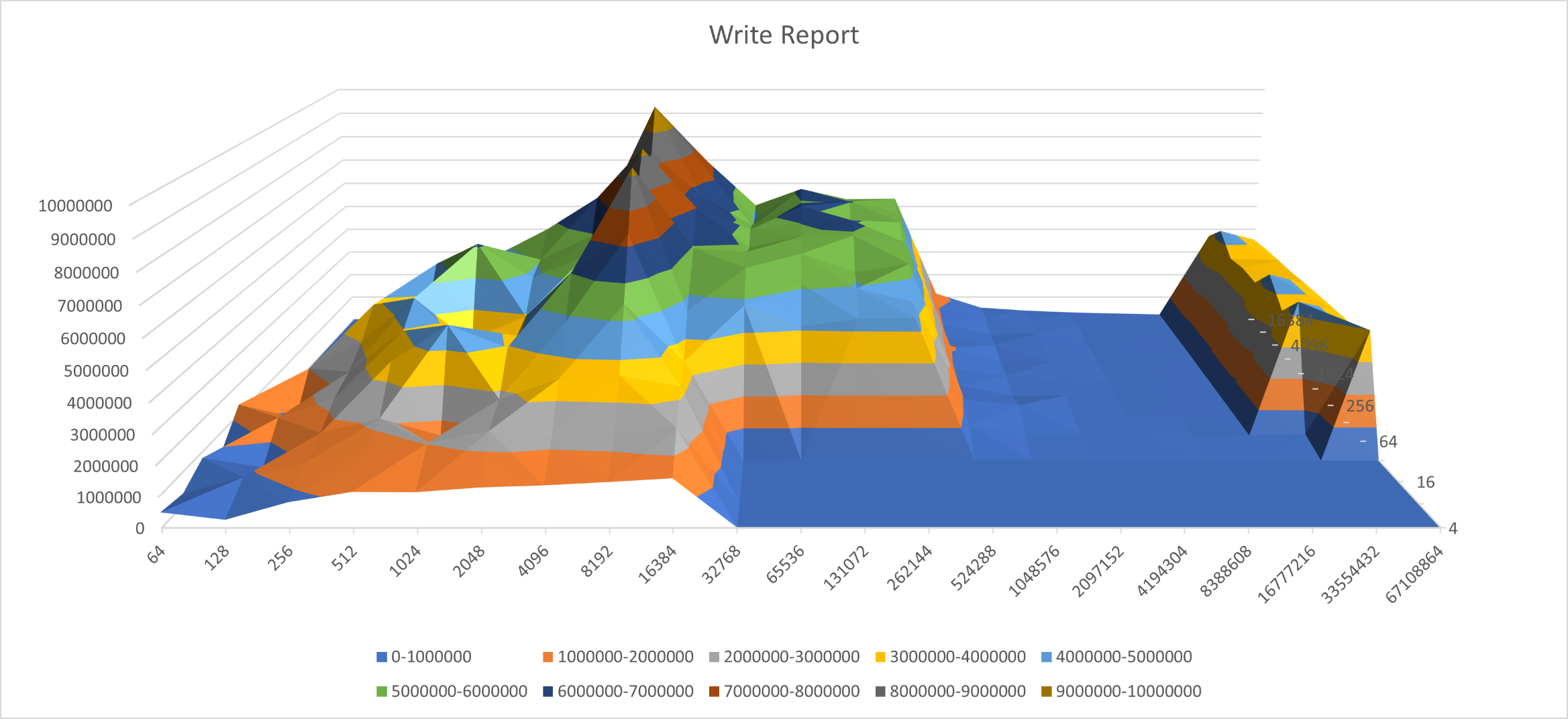
iozone -a -i 0 -g 64G -b HFS_64g.xls
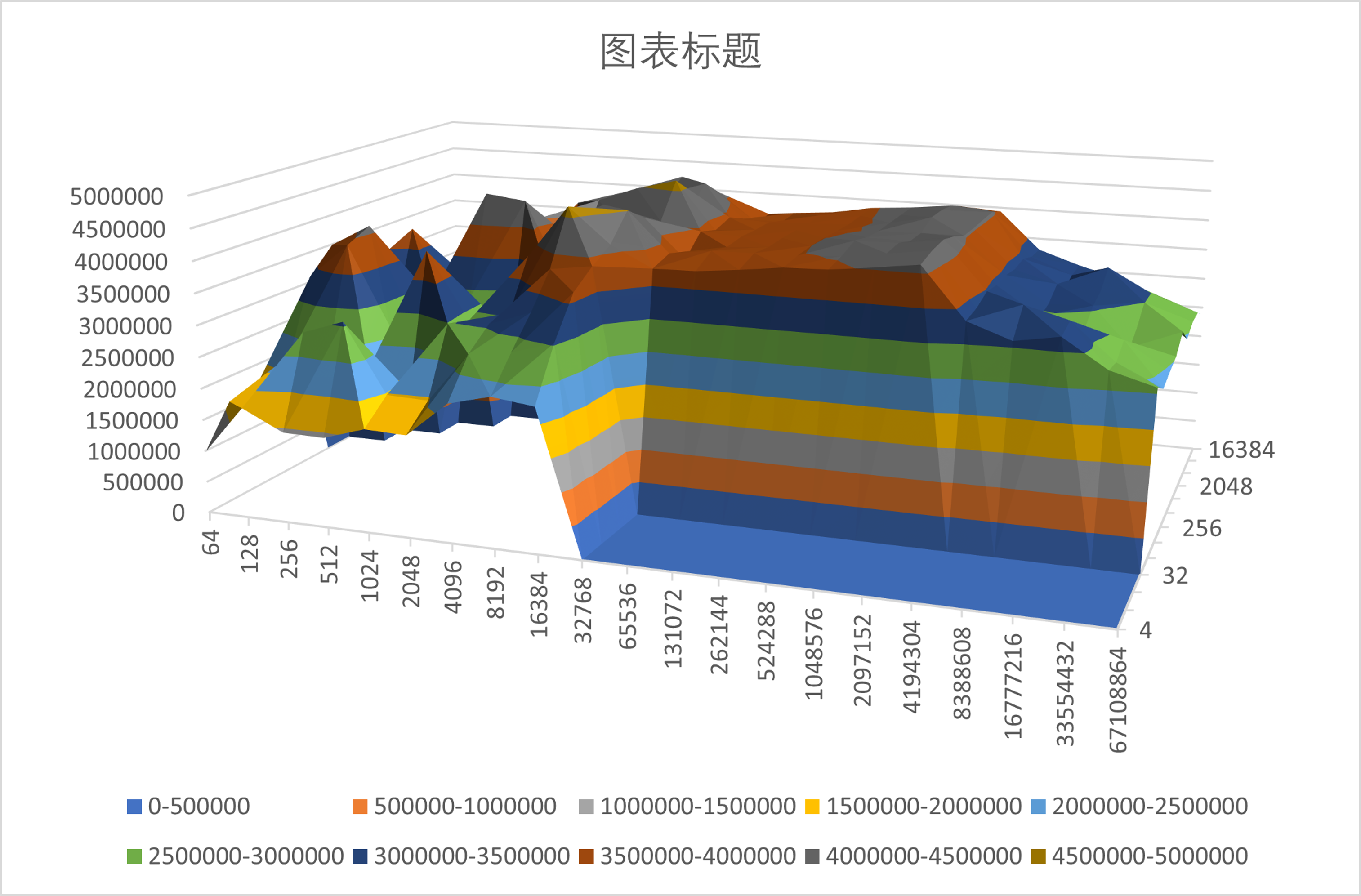
iozone -a -i 0 -g 64G -b SAMSUNG_64G.xls
gnuplot 用着有些问题就直接用 excel 生成图表了(
看出write的性能表现有两个波峰,分别是cache和buffer的数据。随着测试文件size变大,文件操作就变成了磁盘的操作,吞吐量就会下降的非常快。
吐槽:不知道为什么海力士这里在文件大于512M后只有1/10的速率,到32G才恢复到额定速率(3500MB/s),内存策略问题?另一边三星虽然很稳定,但额定速率竟然不如海力士,属实拉了,而且一般的Linux文件系统比Windows快一些,总不会是加装的时候没插好吧
4. Speedometer
Speedometer是苹果WebKit团队开发的网页响应测试工具,通过对模拟用户交互进行计时来测试浏览器的 Web 应用响应能力。
测试地址:Speedometer 2.0 (browserbench.org)
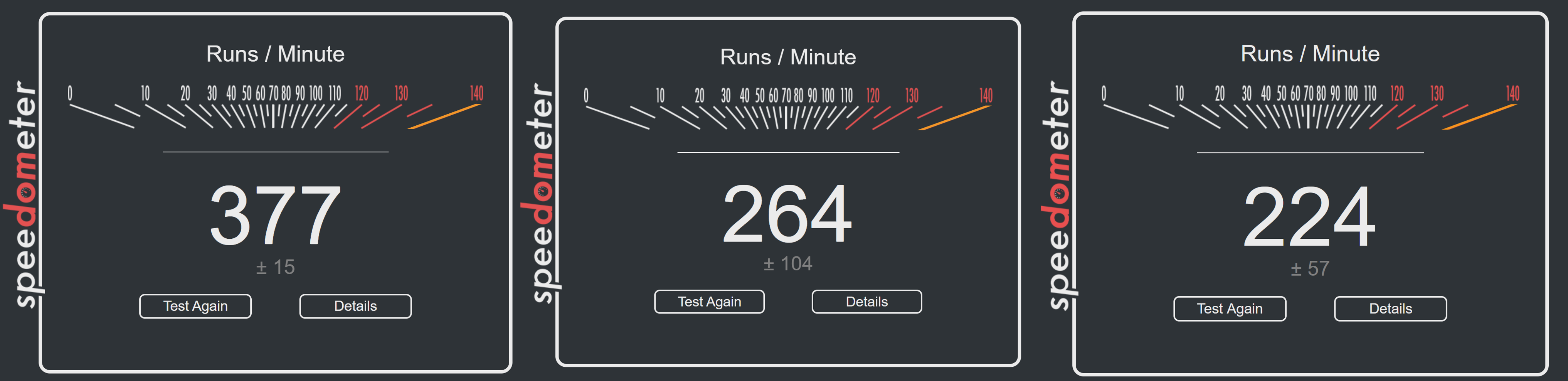
从左到右依次:Chrome 117.0.5938.92,Edge 117.0.2045.36,Firefox 117.0.1
Chrome不愧是最快浏览器,根据 firefox 官方报道,其在 115 版本后的跑分已经接近 Chrome,大约在 170+。影响得分的因素除了浏览器版本外,也与安装的扩展、主机性能(执行JS速率)有关。
四、小结
通过本次实验,于 MIPS 以及其新的定义有了深刻认识,了解到各种类型的系统测评工具,并使用了其中的 Dhrystone、Whetstone、iozone、Speedometer。值得注意的是,在对 CPU 进行评测时,程序不应该受到编译器的过度优化,这正是 Dhrystone 的缺点。
0x04 参考
常见 Benchmark 工具
阅读文献参考
-
c# - What do ‘statically linked’ and ‘dynamically linked’ mean? - Stack Overflow
-
performance - Comparision of Speed of matrix multiplication in matlab and C - Stack Overflow
Dhrystone & Whetstone
-
Dhrystone Benchmark Results - Roy Longbottom’s PC benchmark Collection
-
Whetstone Benchmark Detailed Results - Roy Longbottom’s PC Benchmark Collection
GCC Optimize
iozone
其他Writeup