1. 文本和字符 {#文本和字符 style=”text-align: left;” align=”center”}
在计算机程序中或者数据文件里,[文本(text)]{style=”background-color: #ffff00; color: #ff0000;”}是作为[数字序列]{style=”color: #ff0000; background-color: #ffff00;”}存储的。序列中的数字是具有不同大小、取值和解释的整数。如何解释这些整数是由字符集(character set)、编码(encoding)决定的。
文本主要是由[字符(character)]{style=”color: #ff0000; background-color: #ffff00;”}组成。在格式文本(fancy text, or rich text)中包括显示属性,如颜色、斜体字、上标等,但仍然是以字符组成的纯文本(plain text)为基础的。有时,格式文本与纯文本之间的区别很复杂,依赖于具体的应用。
本文所指的字符是文字和符号的总称,包括文字、数字、字母、标点符号、图形符号、控制字符等。
2. 字符集(编码/编号字符集)
具有数字编码的字符在信息处理中,所使用的整数总有上限,依赖于存储整数的位的数目。这也决定了可以同时区分的字符的数量。 在设计字符集时,首先要决定所需字符的数目,并确定所需字符的清单。根据字符的数目,可以设定整数值的上限,这个整数范围称为编码空间(code space),其中的一个特定整数称为一个码点(code point)。 然后,为字符清单中的每个字符指定一个整数值(码点)。这样就得到一个字符集,称作编码字符集(Coded Character Set)。
注:
(1) 编码字符集的翻译不够准确,应翻译为”编号字符集”为宜(【转】刨根究底字符编码之二——关键术语解释(下)_sinolover的博客-CSDN博客)对字符编号的过程——即确定字符码点值的过程,跟计算机还没有直接关系,可认为是一个纯数学的问题,因为只是将字符与编号(即码点值、码点编号)一一对应起来,根本就还没有涉及到编码算法的问题(即还没有涉及到:根据指定的字符编码方式CEF对编号进行编码以形成码元序列,以及根据指定的字符编码模式CES对码元序列进一步编码以形成字节序列)。
(2) 编号空间中的一个位置(Position)称为码点(Code Point代码点)或码位(Code Position代码位)。一个字符占用的码点所在的坐标(非负整数值对)或所代表的非负整数,就是该字符的编号,又称之为码点值(即码点编号)。经常直接以”码点”指代”码点值”。
(3) 严格来讲,字符编号并不完全等同于码点编号(即码点值)。因为事实上,由于某些特殊的原因,编号字符集CCS里的码点数量要大于抽象字符表ACR中的字符数量。在编号字符集中,除了字符码点之外,还存在着非字符码点和保留码点,所以字符编号不如码点编号准确;但若对字符码点的码点编号称之为字符编号,倒也更为直接。在Unicode编码方案中,字符码点又称之为Unicode标量值(Unicode Scalar Value)
(4) 在Unicode标准中,一个单个的抽象字符,既有可能与多个码点对应(为了与其它标准兼容,比如码点编号为U+51C9与U+F979的这两个码点实际上是同一个字符”凉”,这是为了兼容韩国字符集标准KS X 1001:1998,具体可参看Unicode的官方文档),也有可能使用一个由多个码点所组成的码点序列表示(为了表示由基本字符与组合字符组合在一起所组成的字符,比如à,由码点编号为U+0061的基本字符字母”a”和码点编号为U+0300的组合字符读音符号”、”组成);同时,也并非每一个码点都对应于一个字符,也存在着非字符码点或保留码点。
3. 编码单元、字节和编码
在计算机系统的实现中,整数以特定大小的单元表示,通常为8位(1字节),16位,或32位。在字符编码中,这样的单元称为编码单元(code unit)。根据编码空间的大小和具体要求,来选择合适的编码单元。通常,所选择编码单元对应的整数范围要大于编码空间的整数范围,这样每个码点就只需一个编码单元表示,并且在字符码点与编码单元间的转换非常简便,因为字符码点对应的整数值与相应编码单元的整数值相同。如果编码单元对应的整数范围小于编码 空间的整数范围,就需要多个编码单元表示一个码点。
字节是计算机系统中最基本的表示单元。[[将[字符]{style=”color: #ff0000;”}表示为]{style=”color: #000000;”}字节序列[的过程就称为]{style=”color: #000000;”}编码(encoding)]{style=”color: #ff0000; background-color: #ffff00;”},更重要的是,还包括如何对字节序列进行解释以取得字符。
[字符码点--->码元序列(8位/16位/32位二进制)-->字节序列]{style=”background-color: #ffff00; color: #ff0000; font-size: 16px;”}
+—————–+—————–+—————–+—————–+ | 层次 | 层次名称 | 作用 | 结果 | +—————–+—————–+—————–+—————–+ | 第一层 | 抽象字符表ACR | 字符范围 | | +—————–+—————–+—————–+—————–+ | 第二层 | 编号字符集CSS | 字符编号 | Unicode字符集 | +—————–+—————–+—————–+—————–+ | 第三层 | 字符编码方式CEF | 码元序列 | UTF-8, UTF-16 | +—————–+—————–+—————–+—————–+ | 第四层 | 字符编码方案CES | 物理编码 | 字节序列 | | | | (确定字节序) | | +—————–+—————–+—————–+—————–+ | 第五层 | 传输编码语法TES | 网络传输编码 | base64 | +—————–+—————–+—————–+—————–+
注意,由于字符编码方式CEF与字符编码方案CES中都有”编码”二字,因此,通常所说的动词编码(Encode)有可能指的是通过字符编码方式CEF将编号字符集CCS的字符编号转变为码元序列;也有可能指的是通过字符编码方案CES将字符编码方式CEF的码元序列转变为字节序列。
4. 单字节字符集、多字节字符集 {#单字节字符集多字节字符集 style=”margin-left: 30px;”}
每个字符只使用一个字节表示,称单字节字符集(single-byte character set, SBCS)。双字节字符集(double-byte character set, DBCS)用于为东亚书写系统中所使用成千上万个表意字符提供足够空间。这里的编码仍是基于字节的,不过是两个字节一起表示一个单一的字符。
多字节字符集(multi-byte character set, MBDC),使用可变数目的字节来表示字符。多字节字符集通常与ASCII兼容,也就是说,在这种编码中,拉丁字母使用与ASCII中相同的字节来表示。 一些不常用的字符可能会使用三个甚至四个字节编码。
5. 常见字符集 {#常见字符集 style=”margin-left: 30px;”}
5.1 ASCII: The American Standard Code form Information Interchange 美国信息交换标准代码 {#ascii-the-american-standard-code-form-information-interchange-美国信息交换标准代码 style=”margin-left: 30px;”}
ASCII,它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,后来它被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。ASCII是一个使用7位单元的字符集,及针对7位字节的简单编码方式。尽管局限于很少的一些字符,ASCII是最重要的一种字符集,因为它是目前大多数字符集的基础。 ASCII只提供了128个数字值(也可称作码点,code point),其中33个被保留用作特殊功能(0-31&127,控制字符或通信专用字符)。只有95个码点用作"真正的"可显示文本字符。这些图形字符大多时大写和小写拉丁字母,数字和标点符号,外加一些特殊的括号、下划线和重音符号。在标准ASCII中,其最高位(b7)用作奇偶校验位。
【控制符】LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;【通信专用字符】SOH(文头)、EOT(文尾)、ACK(确认)等;
ISO/IEC 646是国际标准化组织(ISO)和国际电工委员会(IEC)制订的标准,在1972年制订。它是一个 7-位元字符的字集,来自数个国家标准,最主要来自美国的 ASCII(美国信息互换标准代码)。ISO 646 除了英语字母和数字的部分,为所有国家相同外,有些使用字母的国家,可按照实际需要,把 ISO 646 作出修改,以定出该国的字符标准。亦因为当年 8-位元字符集并未得到普遍的接纳,各国把不同的字母或符号放进它们的字符集,以致部分出现在 ASCII 的字母或符号,并没有出现在某些国家的 ISO 646 变体之中。(参考:https://www.fontke.com/article/2424 )
ASCII只使用了一个字节所能表示的256个编码中的前128个(2\^7 = 128)编码,而后128个编码相当于被闲置了。因此,各国针对后面的0x80~0xFF(十进制为128~255)这128个编码分别对应什么样的字符,就有了各自不同的设计。为了结束欧洲各国这种各自为政的混乱局面,于是又先后设计了两套统一的,既兼容ASCII码,又支持欧洲各国所使用的那些衍生字符的单字节编码方案:一个是EASCII(Extended ASCII)字符编码方案,另一个是ISO/IEC 8859字符编码方案。
5.2 EASCII: Extended ASCII 延伸美国标准信息交换码 {#eascii-extended-ascii-延伸美国标准信息交换码 style=”margin-left: 30px;”}
EASCII码同样也是将ASCII中闲置的最高位(即首位)用来编码新的字符(这些ASCII字符之外的新字符,其最高位总是为1)。换言之,也就是将一个字节中的全部8个比特位用来表示一个字符。比如,法语中的é的编码为130(二进制1000 0010)。EASCII码比ASCII码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。
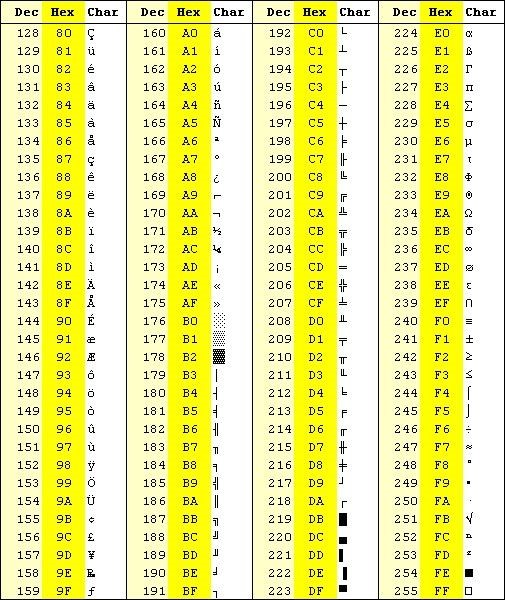 {style=”display: block; margin-left: auto; margin-right: auto;”}
{style=”display: block; margin-left: auto; margin-right: auto;”}
5.3 ISO/IEC 8859字符编码方案 {#isoiec-8859字符编码方案 style=”margin-left: 30px;”}
刨根究底字符编码之四——EASCII及ISO 8859字符编码方案 - 知乎 (zhihu.com)
ISO/IEC 8859字符编码方案:该方案与EASCII码类似,也同样是在ASCII码的基础上,利用了ASCII的7位编码所没有用到的最高位(首位),将编码范围从原先ASCII码的0x00~0x7F(十进制为0~127),扩展到了0x80~0xFF(十进制为128~255)。ISO/IEC 8859字符编码方案所扩展的这128个编码中,实际上只有0xA0~0xFF(十进制为160~255)被实际使用。也就是说,只有0xA0~0xFF(十进制为160~255)这96个编码定义了字符,而0x80~0x9F(十进制为128~159)这32个编码并未定义字符。显然,ISO/IEC 8859字符编码方案同样是单字节编码方案,也同样完全兼容ASCII。
注意,与ASCII、EASCII属于单个独立的字符集不同,[ISO/IEC 8859是一组字符集的总称]{style=”background-color: #ffff00; color: #ff0000;”},其下共包含了15个字符集,即ISO/IEC 8859-n,n=1、2、3...15、16(其中12未定义,所以共15个)。这15个字符集大致上包括了欧洲各国所使用到的字符(甚至还包括一些外来语字符),而且每一个字符集的补充扩展部分(即除了兼容ASCII字符之外的部分)都只实际使用了0xA0~0xFF(十进制为160~255)这96个编码。其中,ISO/IEC 8859-1收录了西欧常用字符(包括德法两国的字母),目前使用得最为普遍。ISO/IEC 8859-1往往简称为ISO 8859-1,而且还有一个称之为Latin-1(也写作Latin1)的别名。
ISO 8859-1 见于默认的 HTML 编码格式!(Eclipse 中)
其中,Latin 1 见于 MySQL 默认的编码格式!
5.4 EBCDIC: The Extended Binary-Coded Decimal Interchange Code 广义二进制编码的十进制交换码 {#ebcdic-the-extended-binary-coded-decimal-interchange-code-广义二进制编码的十进制交换码 style=”margin-left: 30px;”}
EBCDIC是由IBM设计的编码格式,使用8位字节,被一些字符集用于大型机。EBCDIC在与ASCII相近的时期开发的,具有一些相似的特性。
5.5 Unicode:统一码/万国码/国际码 {#unicode统一码万国码国际码 style=”margin-left: 30px;”}
Unicode为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
6. 字节序 {#字节序 style=”margin-left: 30px;”}
7. urlencode {#urlencode style=”margin-left: 30px;”}
在第二篇文章中阐述了四种URL包含汉字的情况:
-
- 网址路径中包含汉字
- 查询字符串包含汉字
- Get方法生成的URL包含汉字
- Ajax调用的URL包含汉字
对于第二种情况,在 Windows10 上测试发现,IE、Edge 和 Firefox 的 HTTP Head 均为UTF-8编码:%E6%98%A5%E8%8A%82